7 minute read
On the surface, Panda is a pretty simple piece of software – upload a video, encode it into various formats, add a watermark or change frame rate, and deliver it to a data store.
Once you spend some time with it, it begins to show how complex each component can be – and how important it is to continuously improve each one.

When Panda was first built, it worked beautifully, and it was quick! But as time went on, and the volume of videos encoded per day increased, it became obvious that to keep pace with increasing speed requirements from customers, and maintain growth – core parts of the platform were going to need to be rethought.
We started looking at each component piece by piece, to find bottlenecks, optimize throughput and keep a fair operating expense so we could retain our price leadership. Panda might be a software platform – but having read the ‘The Goal‘ by Eli Goldratt about a manufacturing plant really reminded us of the process. (It’s a great read btw).
In July we updated to the most current versions of Ruby and Go – and added a memory cache to tasks that were maxing out our instances. Then we tackled the big scale bottleneck – the job manager.
Our biggest bottleneck: the Job Manager
The Job Manager is built to ensure that our customers video queues get processed as close to real-time as possible, and distributes transcoding jobs to the encoder clusters. Whether it’s 2000 encoders on 8 CPU cores each, or 1 encoder on 1 CPU core it’s important it’s allocated correctly.
It monitors all encoding servers running within an environment, receives new jobs, and assigns them to instance pools.
The Panda Job Manager was a single thread Ruby process, which worked well for quite some time. We noticed it would start struggling during peaks, and we had to do something about it. We started looking at where we could optimize it, by identifying each bottleneck one by one.
It was obvious that events processing was too slow in general, but before we even fired up a profiler, we managed to find a huge one just by looking at logs and comparing timestamps.
Redis Queue Architecture
Short digression: We use Redis queues for internal communication, and there was one such queue where all messages for the manager were being sent. The manager was constantly pooling this queue and most of its work was based on messages it received. Each encoding server had a queue in Redis too, and all these queues were used for communication between the manager and encoders.

Because a single Redis queue was used for new jobs as well as manager/encoders communication, huge numbers of the former were causing delays in the latter. And a slow down in internal communication meant that some servers were waiting unnecessarily long for jobs to be assigned.
Is Ruby and Redis the Answer?
The obvious solution was to split the communication into two separate queues: one for new jobs and another one for internal messaging. Unfortunately, Redis doesn’t allow blocking reads from more than one queue on a single connection.
We were forced either to implement Redis client that would use non-blocking IO to handle more that one connection in a single thread, or resort to multiple threads or processes. Writing our own client seemed like a lot of work, and Ruby isn’t especially friendly if you’d like to write multithreaded code (well, unless you use Rubinius).
Before trying to solve that, we launched manager within a profiler to get a clearer picture. It turned out that roughly 30% of time was spent at querying the database (jobs were saved, updated and deleted from the DB), and the remaining 70% was just running the Ruby code. Because we were a few orders of magnitude slower that we wished, optimizing neither just the database nor the Ruby code would be enough (and we still had to solve the queues issue). We needed something more thorough that a simple fix.
Go baby, GO!
 We started by rewriting the manager in Go. We didn’t want to waste time on premature optimization, so it roughly was a 1:1 rewrite, just a few things were coded differently to be more Go-idiomatic – but the mechanics stayed the same.
We started by rewriting the manager in Go. We didn’t want to waste time on premature optimization, so it roughly was a 1:1 rewrite, just a few things were coded differently to be more Go-idiomatic – but the mechanics stayed the same.
The result? Those 70% that were previously spent on Ruby code dropped to about 1%! That was great, we got almost 70% speed-up, but we were still nowhere near where we wanted.
Multithreading
Then we fixed the queues issue. With Go’s multithreading model is was so simple that it’s almost not worth mentioning – we even accidentally got a free message pre-fetching in a Go channel (another thread pools Redis and pushes messages to a buffered channel). And this was a huge kick – now we could handle more than 16,000,000 jobs per day per job manager.
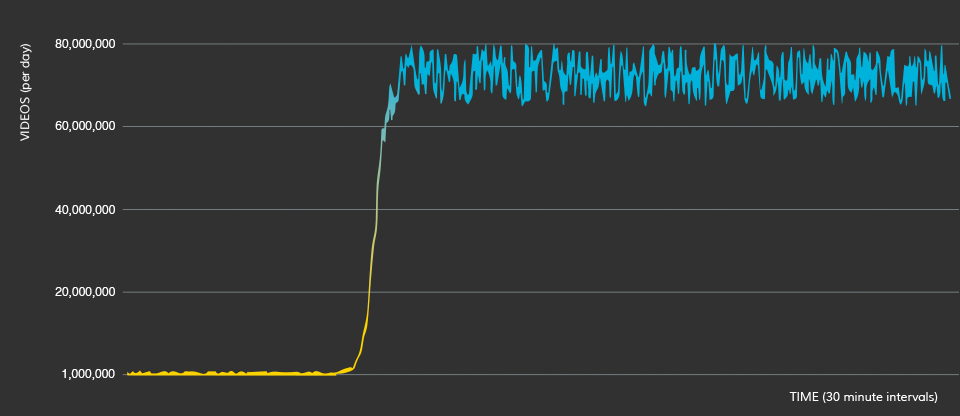
We could have pushed it harder, but we still hadn’t even started profiling our new Go code at this point. Golang has great tools for profiling, so rather quickly we were able to go through the bottlenecks (it was database almost all the time). When we decided that it’s enough, we started testing… And we just couldn’t get enough EC2 instances to reach manager’s limit. We ended at about a bit less than 80,000,000 jobs per day and even a sign of sweat wasn’t visible on manager.
The graph below shows the number of videos per day projected from the number of videos processed within the last 30 minutes. We started at a bit more than 1,000,000, then switched to the Golang manager and got to the 80,000,000 limit – but there were no more jobs (we reached our EC2 spot limits while performing the benchmark!), so we might have processed even more (but it should be a safe number for some time).
The end result of this phase is a technical architecture that clears queues much faster, and for the same encoder price, delivers better throughput and greatly enhanced encoder bursting (especially good during the holiday season where we often have customer that ratchet up activity by 100x!), and more automation. We’re not done yet – and we have some fantastic features coming in 2015 that the new back-end enables us to deliver.
PS. Kudos should also go to Redis – it’s a fantastic, very stable and battle-tested piece of software. Big thanks, Antirez!
Do you have a suggestion or have some knowledge you’d like to share with us? We’d love to hear from you – get in touch support@pandastream.com anytime (we’re 24×7).











 Apple released its flagship device, the iPhone 6 and iPhone 6 plus a few weeks ago, and according to Tim Cook, it’s their
Apple released its flagship device, the iPhone 6 and iPhone 6 plus a few weeks ago, and according to Tim Cook, it’s their 