Getting Started - Creating a Project
Everything in Timed Text Speech service happens within a Project. This is where you define:
- language that will be used for transcription (base transcription model)
- custom vocabulary (optional) that helps to improve results by adding names, acronyms, places, specialized terms, etc.
Transcription jobs are submitted to a Project for processing and once finished the are ready for review and edition if needed.
Setting up a Project is pretty straightforward process, we did our best to make it as easy as possible.
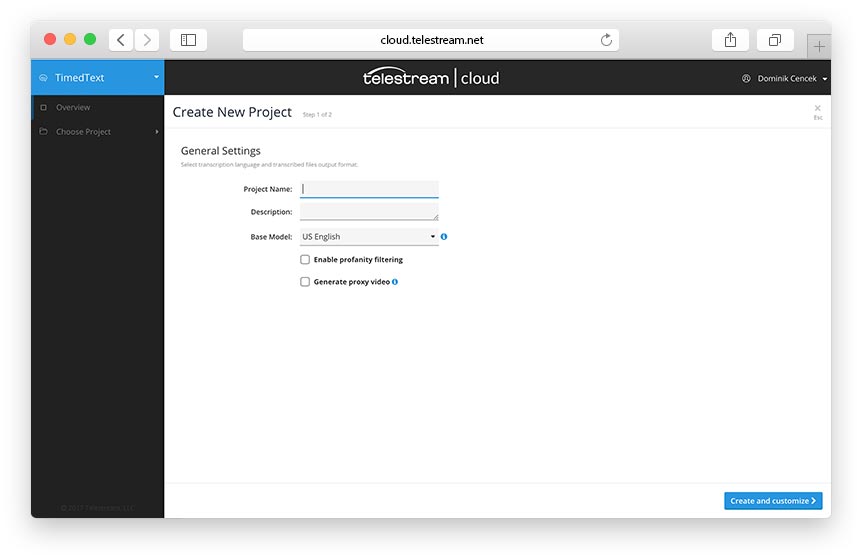
When creating a project - apart from naming it - you need to pick the transcription output format and base language model. Model contains many words that are used in everyday conversations and would be sufficiently accurate for a variety of general applications. However, it can lack knowledge of specific terms that are associated with particular domains.
How do you address that? You may optionally add custom vocabulary that is specific to certain domain - law, sports, medicine, technology, and so on. It can be done in two ways. By uploading corpus files or adding words manually.
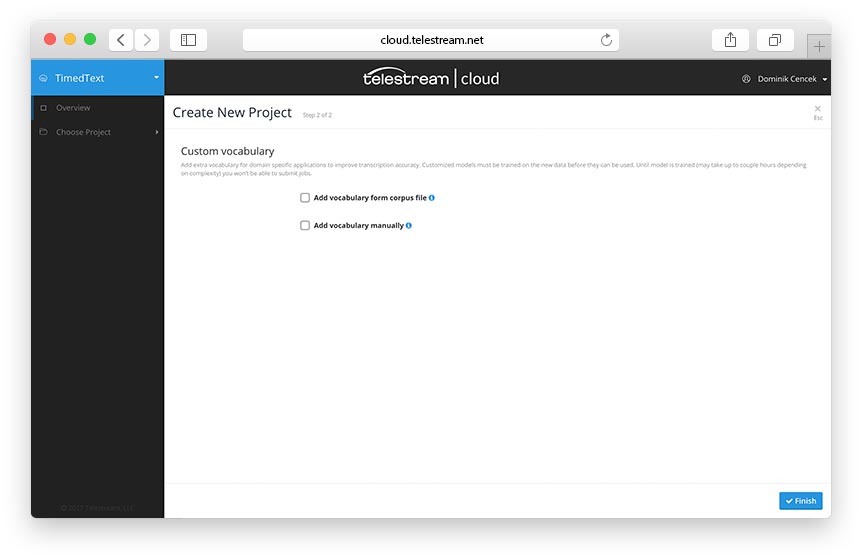
A corpus file is plain UTF-8 text file that ideally contains sample sentences with domain specific words used in the context they usually appear in, to improve recognition accuracy. If you already have or plan to create corpus files please make sure each sentence is in a separate line and uses consistent capitalization.
You can also add words manually - again using separate lines for each word or sentence is essential. Custom vocabulary can be added or updated later in the Projects Settings.
If you added custom vocabulary then speech recognition engine needs to be trained on using it properly. This may take some time and until then you won’t be able to submit jobs to the Project.